Over the summer I have been working at improving the Computer Vision capabilities of Flux. My specific line of work was to add newer models to the Flux model-zoo, implement some new features and also improve the speed of the previous layers. Specifically, I achieved a 18-fold speed up for the Convolutions and around 3-fold for BatchNorm.
A Short Summary of my work during GSoC 2018
I am listing all the essential PRs I had made during this project. Some of them are merged, some are unmerged, and some are even a work in progress. We discuss only major PRs, leaving out bug fixes and small patches. So here they are
The following new packages were developed during the course of this project.
A Walkthrough of the Pull Requests
Let's go through these changes one by one.
Add a wrapper for CUDNN BatchNorm
Flux currently lacks a dedicated GPU Kernel for BatchNorm. BatchNorm is one of the most important layers of Neural Networks, and they speed up training by dealing with the internal mean covariance shift. Until now we were using the Flux CPU code for BatchNorm (which obviously will be slow). So this PR aims to solve this problem by wrapping the CUDNN Batchnorm Layer and integrating it with the Flux AD. Some highlights of the speed (and memory consumption) improvements are 1.860 s (1367 allocations: 50.92 KiB) -> 2.782 ms (276 allocations: 10.38 KiB). I am benchmarking the total time (forward + backward) of BatchNorm(100) for a 224 * 224 * 100 * 10 sized array. This PR is yet to be merged. It needs to be updated to Julia 1.0 (which is supported by the Flux master) before merging.
Speed up the CUDA Convolutions in Flux
I performed benchmarks between Flux and Pytorch (read on to know more about that). We went on profile the neural networks and found some issues in Flux Conv Layer. The major bottleneck was in the broadcasted bias addition that we were performing. So instead of using the broadcasted bias addition we use cudnnAddTensor for CUDNN Version prior to 7.1. For anything above 7.1, we shift to using cudnnConvolutionBiasActivationForward with the activation always being identity and finally dispatch over the other activations. The major improvements to speed using this update reflects in the DeepLearningBenchmarks repo. Also, this PR depends on a CuArrays PR, so it cannot be merged until the CuArrays has been merged. Also, it requires updates to be able to adapt to Julia 1.0.
Native Julia Depthwise Convolutions in Flux and NNlib
Depthwise Separable Convolutions are vital for Mobile Applications of Deep Neural Networks. MobileNets and Xception Net make direct use of this form of Convolution. So it is quite essential for a deep learning library to support such convolutions out of the box. Firstly this involved implementing the CPU version of the code in NNlib. Then we just need to the hook up the depthwise convolution into the Flux AD. Out of box support also allow some of the to be added models in Metalhead.jl and model-zoo to be easily defined. As a part of some future work on this topic, there needs to be a CUDNN binding for this algorithm.
Adding support for more CUDNN Convolution Algorithms
There are a variety of Convolution Algorithms around. All these use the properties of the input tensor, and the filter tensor and have very specialized routines developed for efficient convolutions. Thankfully CUDNN has these specially developed convolution routines built into it. So we need to integrate it directly into CuArrays and expose its API for use from other packages like Flux. The wrappers for a simple convolution operation was pre-written in CuArrays. So we only need to create the wrappers for workspace allocation. This PR adds the necessary wrappers and changes the convolution function definitions to expose the API for algorithm change. So for the end user, the only change would be to change the keyword argument algo.
Add wrappers for more Convolution and Activation Functions
When benchmarking the Flux Convolution Code, we figured out some of the major bottlenecks that were coming out of the Backward Pass for Convolution Bias. Hence the natural choice was to wrap the CUDNN Function which efficiently calculates the Gradient for Bias. Also, we were able to wrap a function for applying activation and adding bias at the same time. To use this function, cudnnConvolutionBiasActivationFunction we needed to wrap the Activation Forward and Backward Pass functions. Now lets see what kind of speed improvements we achieved with this update.
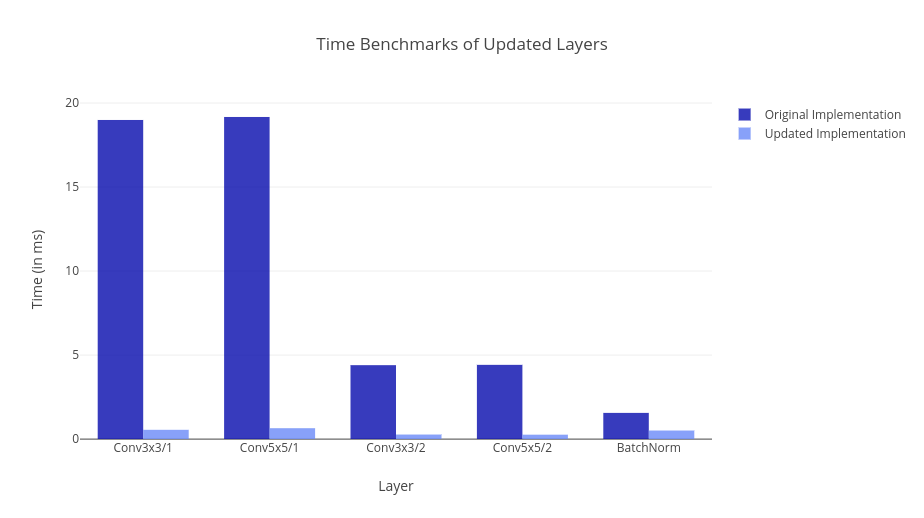
Fixing the API of new Metalhead models
Some models like GoogleNet and Resnet were added to Metalhead recently (special thanks to Ayush Shridhar [@ayush1999] for his work on ONNX.jl). However, this code is generated automatically and not necessarily human readable. Moreover, the only thing we could do we these models was to perform predictions. We can't use it for something like feature extraction. So we ported some of my models from the model-zoo and manually load the weights into it. For more detailed usage of Metalhead go here.
Improve the accuracy of Metalhead models
The accuracy of the existing loaded models into Flux was pretty bad. We had already tried out a variety of preprocessing steps but mostly of no use. After some trial and errors, we were able to figure out the primary reason. We were using the weights for Cross Correlation Operation in place of a Convolution Operation. For now, this is fixed by manually flipping the weights before loading them. As a long-term solution, we are exposing the parameter to choose between convolution and cross-correlation in NNlib and eventually in Flux.
Add bleeding edge Computer Vision models in Metalhead
This part of the project is still in its infancy. Most of the work for this is done (but it is mainly scattered in model-zoo). The model zoo is essentially is targeted to allow users to import all sorts of models in their code. The models might be untrained (which most of the models are currently are). So the primary motivation is that if we want to train a ResNeXt model, we don't have to redefine something which has already been done by someone. We should be able to load the model without any effort.
model = VGG19() # This fetches an untrained VGG19 model
model_trained = trained(VGG19)
# Get the trained VGG19 model. This is the same as previously calling VGG19()
trained(VGG11)
# We get an error as we don't currently have a trained VGG11 model but VGG11() works fineBrief Description of the Packages
DeepDream.jl
This package provides a simple API to generate dreams on the desired image. You need to provide the image, choose what type of dream you want and which model to use. This package relies on Flux and Metalhead for its trained models.

The above image was generated using guided deepdream.
CNNVisualize.jl
Over the years several visualization algorithms have been developed to understand the functioning of neural networks. This package aims to implement such algorithms. Most of these, are going to work out of the box for Metalhead. This is currently a work in progress package, however, most of it is complete.
Here's a small demo of the package
FastStyleTransfer.jl
This is the implementation of the paper Perceptual Losses for Real-Time Style Transfer and Super-Resolution. There are some obvious deviations from the paper. We used the best layer implementations that were currently available in Flux. As for the exact architecture it is still in development. We provide three pre-trained models with this package. The API has been kept as simple as possible.
Below is a small example of style transfer on MonaLisa
![]()
Overview of the Work done in GSoC 2018
As you can see from the above PR descriptions a lot of my work has been around benchmarking Flux models and making speed ups wherever possible. The initial part of my job was to add some new computer vision models to the Flux model-zoo. So we added models like VGGNets, ResNets, DenseNets, etc. to the Flux model-zoo. Also, we were able to port some of these models to the Metalhead package which is specially designed to address Computer Vision problems. After lots of experimentation and help from some people of the JuliaLang community, we were able to fix some of the accuracy problems we were encountering. Next, we went on to develop a package to perform FastStyleTransfer. It allows users to easily train their models and also stylize images with great ease. We was also able to train some of the densenet models and recreate the results of the MURA paper.
Next up was to perform benchmarks for the current implementations in Flux and solve the bottlenecks wherever possible. So we wrote the benchmarking scripts for Flux and Pytorch and performed heads on comparison between them. For the first time, it turned out that Pytorch is much faster than Flux. However, we were able to find the reason for this slow speed. Turned out it was because of the lack of a specialized kernel for broadcasted addition and its backward pass. So the immediate solution was to wrap some of the CUDNN Functions and integrate them with Flux. Doing this actually brings down the time taken by those layers a lot. Currently, we are at-par with Pytorch wrt the time for each of the individual layers.
Experience at JuliaCON
I was able to attend JuliaCon 2018 in London. Thanks to The Julia Project and NumFOCUS for funding this trip. I got the opportunity to present a poster on the work I had done during my GSoC. It was the first conference I was attending, so it was indeed quite a unique experience. I was able to share my work with other people and even got some valuable advice regarding it. Also, I discovered some new cool open-sourced projects that I would like to contribute to in the future. Finally, it's always a pleasure to meet the people I have been interacting with in Slack.
Why use Julia and Flux for Deep Learning?
There is a brilliant post on how Julia can play its part as a Language for Machine Learning. That post summarizes the reasons from the viewpoint of people highly experienced in the field of Machine Learning. Here I shall be presenting the reasons from a layman's point of view.
Just think about implementing a standard Computer Vision model in one of the popular frameworks, like Pytorch or Tensorflow. It's pretty simple, right? Just call the necessary layers using their API, and you're done. Now imagine having to define something that is not present in their standard library. You need to first write your custom layer (both forward and backward passes, in case you are wondering) in C++ and if that was not hard enough you go about to define the GPU Kernel for that code in CUDA C. Now you integrate this layer (obviously in Python) with Pytorch or Tensorflow as per their particular API. And good luck debugging the SegFaults that you get.
Now let's see how you do that in Flux. You start by writing the layer in Julia and its CUDA GPU version using CUDAnative (cheers to Tim Besand [@maleadt] for his excellent work). As for integration into the Flux AD you simply use the @grad macro. It's that simple!
One complaint you might be having is the unavailability of a lot of trained models. However, thanks to ONNX.jl and Keras.jl the problem is more or less resolved. Both of these are the work of Ayush Shridhar. Using these you can use models trained using Pytorch or CNTK, as long as they are stored in ONNX format. Also, now you have a wide range of Reinforcement Learning Models like AlphaGo.jl (by Tejan Karmali) written using Flux besides the Computer Vision models in model-zoo and Metalhead.jl.
Future Works for the Project
This Project has deviated highly from what I had initially proposed but its mostly for good. The things implemented as a part of this project should surely help in the faster training of Deep Neural Networks in Flux and also help create more complicated models using Flux. That being said an exciting thing for the future of this Project would be to complete the addition of Object Classification models in Metalhead as proposed in this issue. Another interesting thing to have would be some Object Detection models built using Flux in one place. Also, we should continue to solve the current bottlenecks that are left to be addressed. We should keep adding the benchmarks to DeepLearningBenchmarks which is vital for the identification of bottlenecks.
Acknowledgements
Firstly, I should thank Google for organizing Google Summer of Code which gave me this excellent opportunity to work with the Open Source Community. Also, I thank NumFOCUS and JuliaLang for selecting me to work on this project. Next, I would thank my mentors Viral Shah and Mine Innes for their constant support and guiding me through my project. Finally, let me thank the brilliant JuliaLang Community for clearing my doubts and being an excellent source for learning.
![]()